Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
In this deployment, the meta-llama/Llama-2-70b-hf pretrained model is used, which generates a continuation of the incoming text. But to access this model you must have access granted by the Meta. Nothing complicated, but it’s a bit inconvenient, so someone created their own Hugging Face repository cryptoman/converted-llama-2-70b with this model weights with open access, since the license allows it.
There is also a meta-llama/Llama-2-70b-chat-hf model that are optimized for dialogue use cases and can answer questions. The “converted” and “hf” in the model names means that the model is converted to the Hugging Face Transformers format.
In this deployment, the model is loaded using QLoRa. It reduces the memory usage of LLM finetuning without performance tradeoffs compared to standard 16-bit model finetuning. This method enables 33B model finetuning on a single 24GB GPU and 65B model finetuning on a single 46GB GPU. QLoRA uses 4-bit quantization to compress a pretrained language model. Model loads in 4bit using NF4 quantization with double quantization with the compute dtype bfloat16 More details can be found here.
Deploying
This model require >40Gb of GPU VRAM. Tested on NVIDIA A6000 and H100 GPUs.

You’ll need more than 300 MB of VRAM is not enough to work on NVIDIA A100. Using that amount the application starts, but when the generation function is called, the error “CUDA error: out of memory” appears.
{kind=link}
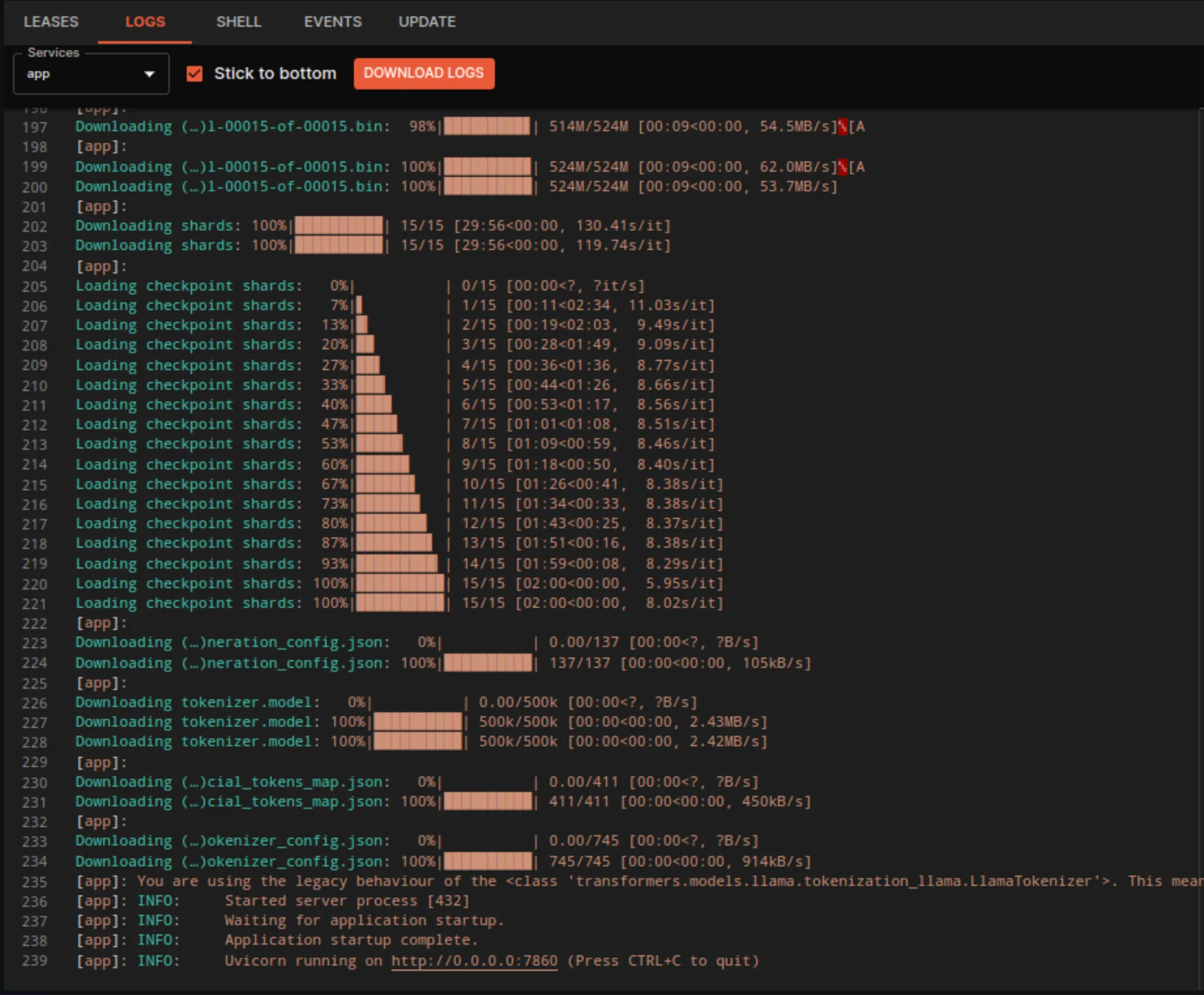
When the deployment begins, 15 model weights files will be downloaded with a total of 130 GB and loaded into memory, and this may take some time. You can watch the loading process in the logs.
Use this SDL to deploy the application on Akash. There are two environment variables in SDL:
-
MAX_INPUT_TOKEN_LENGTH- this value specifies the maximum number of incoming text tokens that will be directly processed by the model. Text is truncated at the left end, as the model works to write a continuation of the entered text. The larger this value, the better the model will understand the context of the entered text (if it is relatively large text), but it will also require more computing resources. -
MAX_NEW_TOKENS- this value specifies how many new tokens the model will generate. The larger this value, the more computing resources are required.
These parameters must be selected depending on the tasks that have been applied to the model and the power of the GPUs.
Logs
The logs on the screenshot below show that the loading of the model weights files has completed and the Uvicorn web server has started and the application is ready to work.