Get Started
Accelerate AI on AkashML
Rent high-performance GPUs instantly for machine learning workloads. Launch pre-configured environments for model training, fine-tuning, and inference without the complex infrastructure setup.
Launch AkashML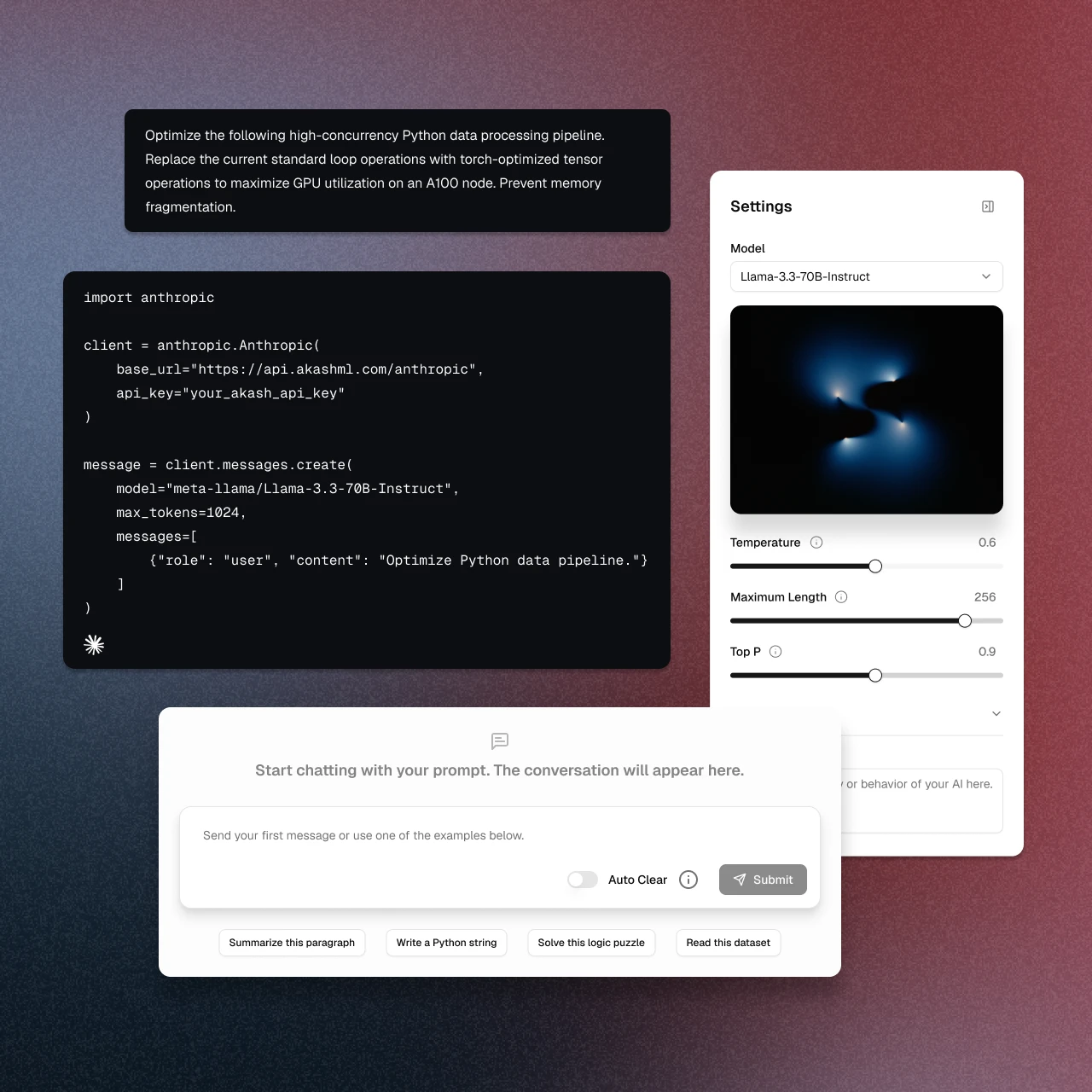
Deploy on Akash Console
Migrate your Docker containers to an independent cloud network. Use pre-built templates or supply an SDL configuration file to spin up raw compute directly on sovereign infrastructure.
Deploy Now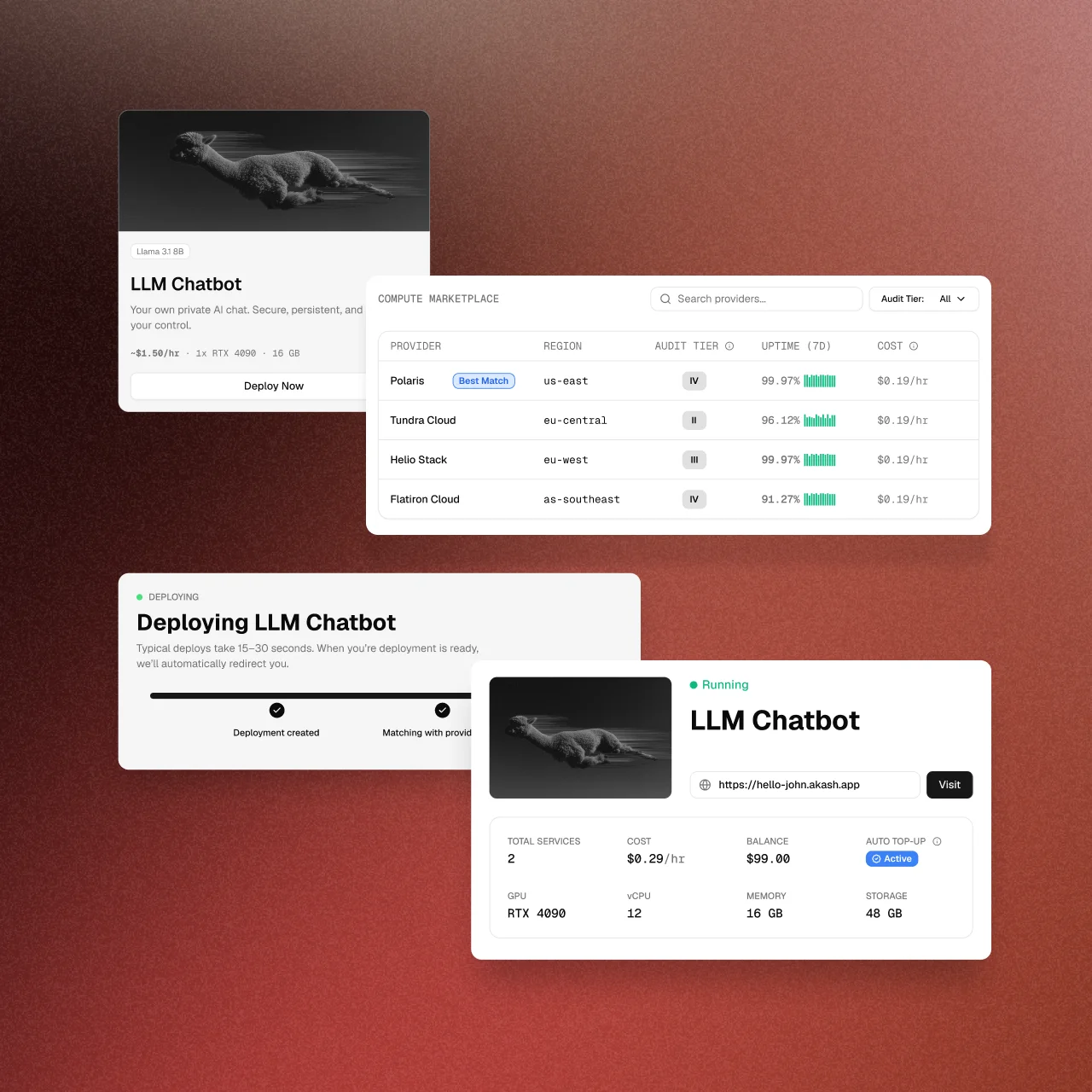
Become a Compute Provider
Monetize your idle server capacity. Run our provider software to list your GPU and CPU hardware on the global network and automatically earn revenue from enterprise deployments.
Become a Provider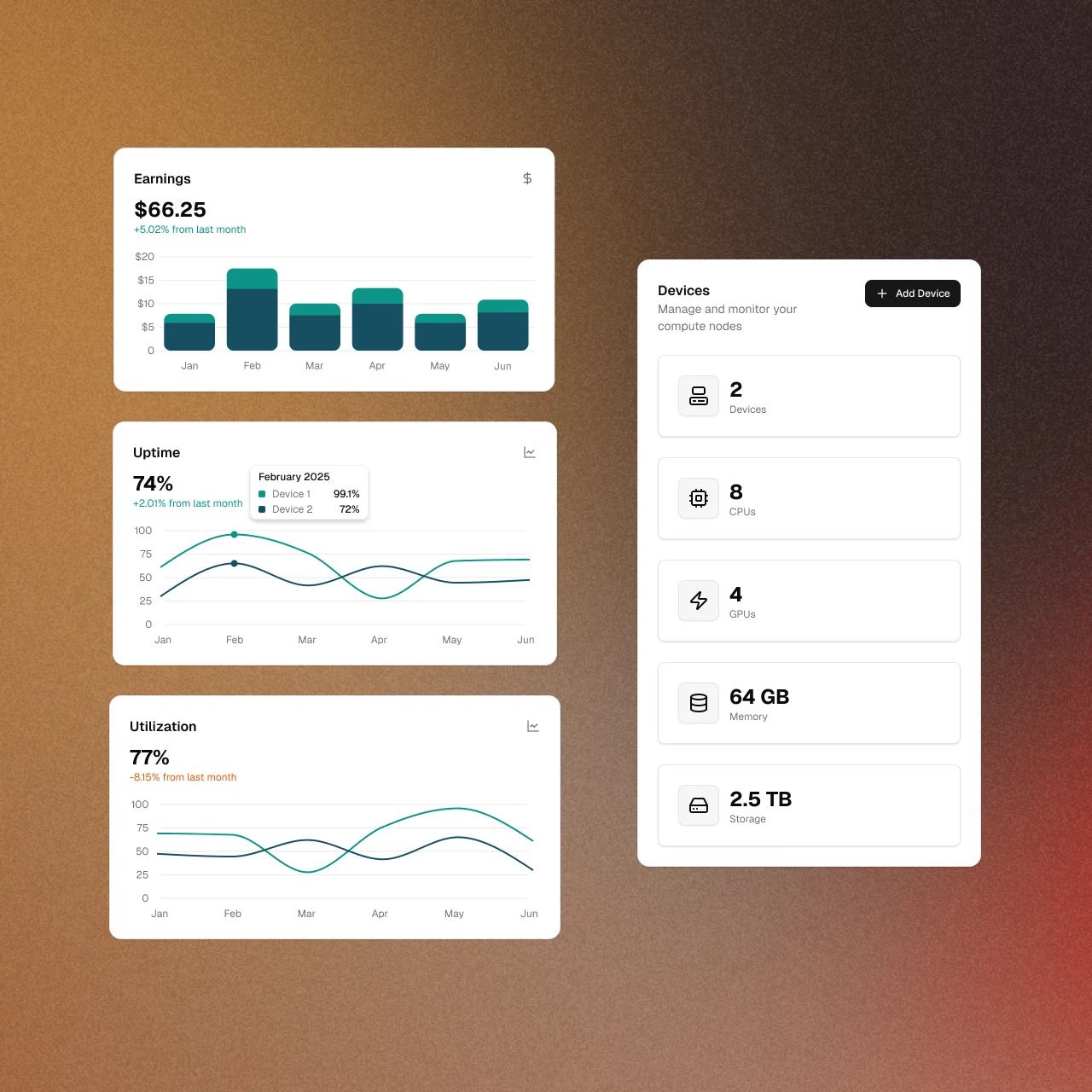
Get Started
Accelerate AI on AkashML
Rent high-performance GPUs instantly for machine learning workloads. Launch pre-configured environments for model training, fine-tuning, and inference without the complex infrastructure setup.
Launch AkashMLDeploy on Akash Console
Become a Compute Provider
The Efficiency Gap
Market-driven pricing vs. legacy markups.
Choose a GPU Model
Why the gap? Legacy providers set static rates to protect corporate margins. Akash prices are determined by a global reverse auction to maximize hardware utilization. You pay for the silicon, not the provider's overhead.
How It Works
Go from configuration to an active workload in seconds.
Configure your deployment
Select a template or supply your own container image. Specify required resources like GPUs, region, and maximum price to send your request out to the network.

Llama 3.1 70B
Image
Model
GPU
CPU
Memory
Max price
Automated bidding
Independent infrastructure providers meeting your exact requirements automatically submit competitive bids in real time. You see who is offering the hardware and the precise rate.
Authorize and execute
Accept the optimal bid to open the lease. The network handles the backend routing instantly, initializing your container and spinning up a live endpoint for your workloads.
How It Works
Go from configuration to an active workload in seconds.
Configure your deployment
Select a template or supply your own container image. Specify required resources like GPUs, region, and maximum price to send your request out to the network.
Automated bidding
Authorize and execute
Llama 3.1 70B
Image
Model
GPU
CPU
Memory
Max price
Supercloud for AI
Stop overpaying for gated compute. Deploy on a global marketplace of high-density GPUs to maximize your engineering runway.

Docker Native
No refactoring. If it runs in a container, it runs on Akash. Migrate your stack from legacy providers with zero changes to your application code.

Train 3x Longer
H100s for $1.33/hr vs AWS at $3.93/hr. Get nearly 3 hours of compute for the price of 1. Transparent pricing, no hidden fees.

1-Click Templates
Launch pre-configured environments for Llama 3, DeepSeek, and Stable Diffusion in seconds. Move from configuration to active container in less than 60 seconds.

Global Silicon Supply
Access enterprise-grade H100s and A100s alongside high-performance consumer RTX 5090s. Scale from single-node inference to massive interconnected training clusters on demand.

Ray Distributed Clusters
Scale your machine learning workloads instantly. Provision multi-node Ray clusters to train and fine-tune large-scale models natively, eliminating complex manual cluster orchestration.

Operational Autonomy
Retain absolute control over your network routing and data residency. Moving away from closed, proprietary ecosystems protects your application stack from single-provider lock-in and vendor dependencies.
Razer Powers Viral AI
Inference on Akash
To scale its global AVA Mini campaign, Razer integrated its open-source AIKit platform with the Akash independent compute network. By pooling distributed high-performance consumer GPUs behind a single managed endpoint, the engineering team achieved reliable elastic scaling with zero manual infrastructure intervention.
$0.01
per generated image
3.24s
avg. end-to-end response time
15x
lower inference costs than centralized APIs

"The future of AI isn't just better models – it's efficient infrastructure. With Razer AIKit, many use cases already run locally. With Akash Network, we extend that into a decentralised cloud to scale efficiently."
QUYEN QUACH
Vice President of Software, Razer
Global Grid. No Off Switch.
Access a global network engineered for high availability. While centralized clouds rely on single points of failure, Akash uses a distributed protocol to keep your workloads independent and resilient against system-wide failure.
61
Active Providers
15k
vCPUs
434
GPUs
90 TB
Memory
768 TB
Storage
Start Building
Launch containerized AI workloads via our self-serve console, or coordinate custom enterprise infrastructure configs with our team.